
Scalable Machine Learning for Small Teams
Nowadays, Data Scientists are expected to build distributed systems that are scalable and robust. The systems can run distributed programs in parallel but must be resilient to recover from failures. In this project, I will build a scalable system with solid tools such as PySpark which let a data scientist build end-to-end programs more efficiently and quickly.
For teams of small size (like start-ups, small companies, or limited budget and resource projects), we want to take advantage of the handful of tools (such as cloud environment and existing ML libraries).
Google Cloud Platforms provide a lot of solid environments and tools for managed solutions. For example, in the case of Kafka, if we want to host Kafka services by ourselves, there are many tasks to do including: managing the server, adding worker nodes, dealing with problems, and updating/fixing bugs which means that we need more data engineers. However, Google Cloud Dataflow or Pub/Sub can provide the same functionalities but less headache to manage and maintain the servers. So that the team now can focus on building the model with little care about the server, environment, and dependencies.
In this project, I mainly use services from GCP.

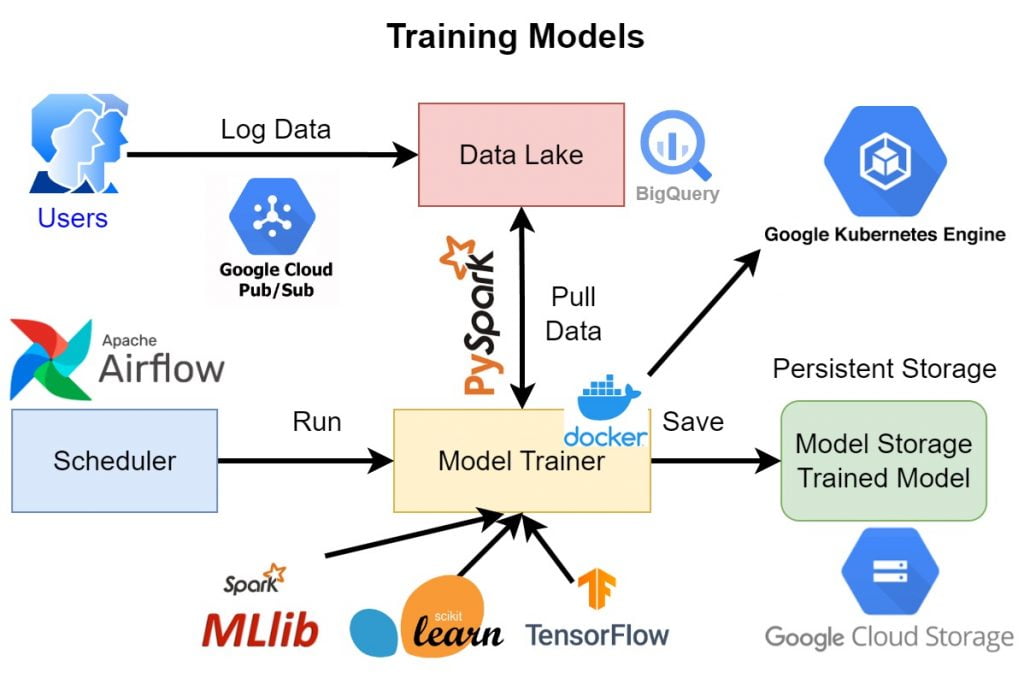
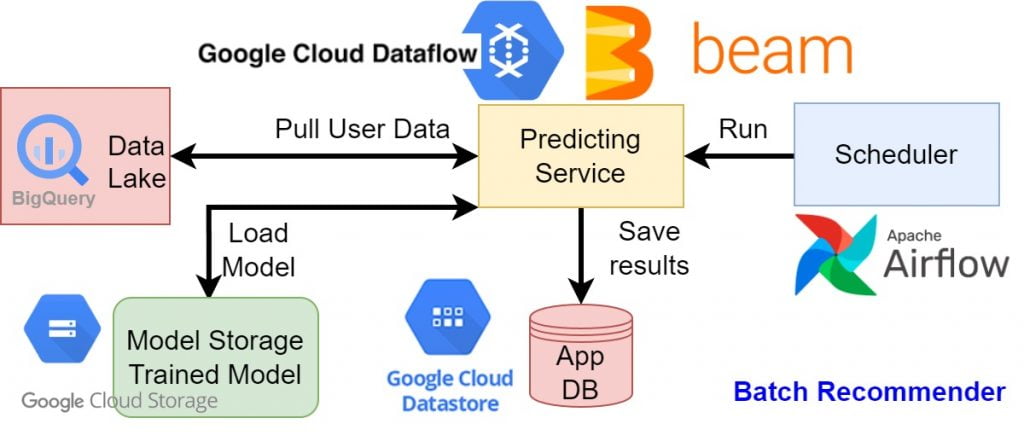
All files on GitHub: https://github.com/linhhlp/Scalable-Machine-Learning-for-Small-Teams
You May Also Like

Recommendation systems: Amazon Products and Reviews

Zimbra multi-tenancy service
