Sequence to Sequence (seq2seq) Model is one of the most important frameworks in NLP which includes many applications like chatbots (Text generators), text summarization, and translators.
Recently, seq2seq is empowered with Machine Learning in both encoder and decoder models. These models are both language models and are often built with LSTM (Long short-term memory) models.
First, text input is fed to the encoder (sequence), the output of this is fed to the decoder (to), and the final output is transformed back to the text (sequence).
Because this task is sequence-based, we can use Recurrent Neural Networks (RNNs) or Gated Recurrent Units (GRU) (computationally more efficient than LSTM) depending on the design of the system and accuracy requirement.
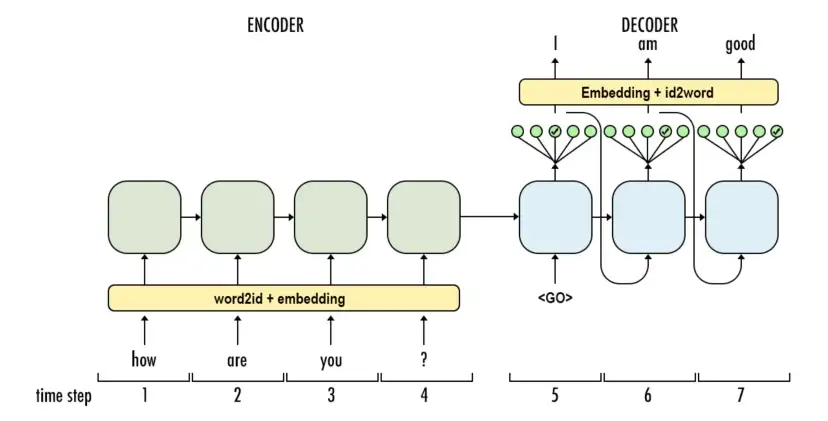
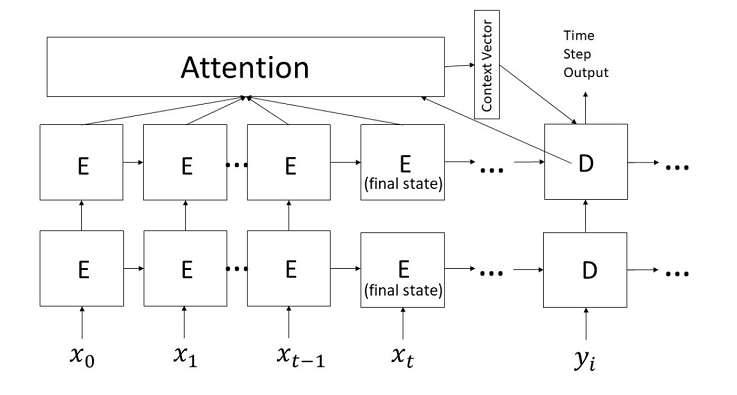 (source educative.io)
(source educative.io)