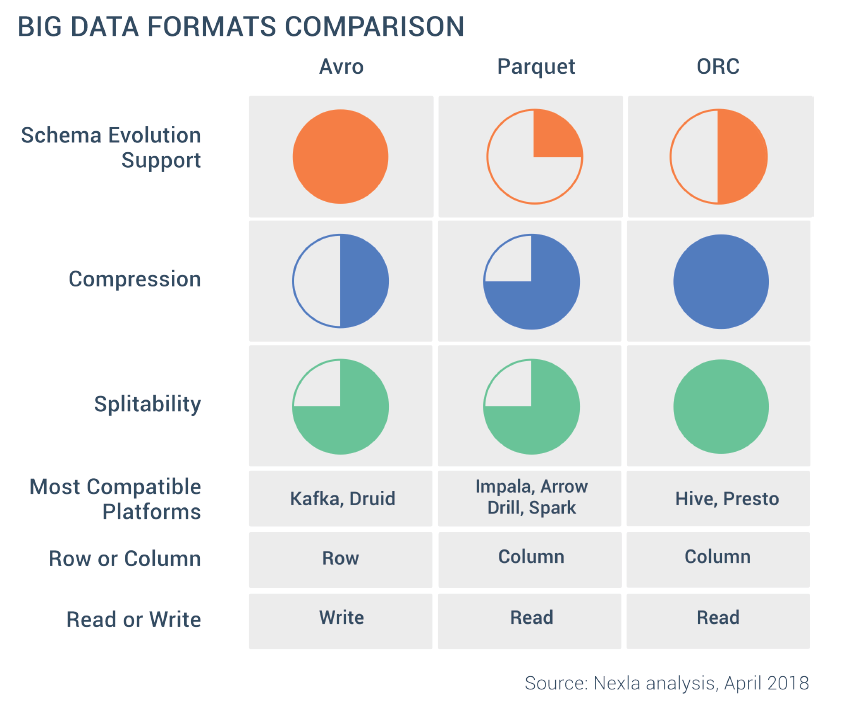
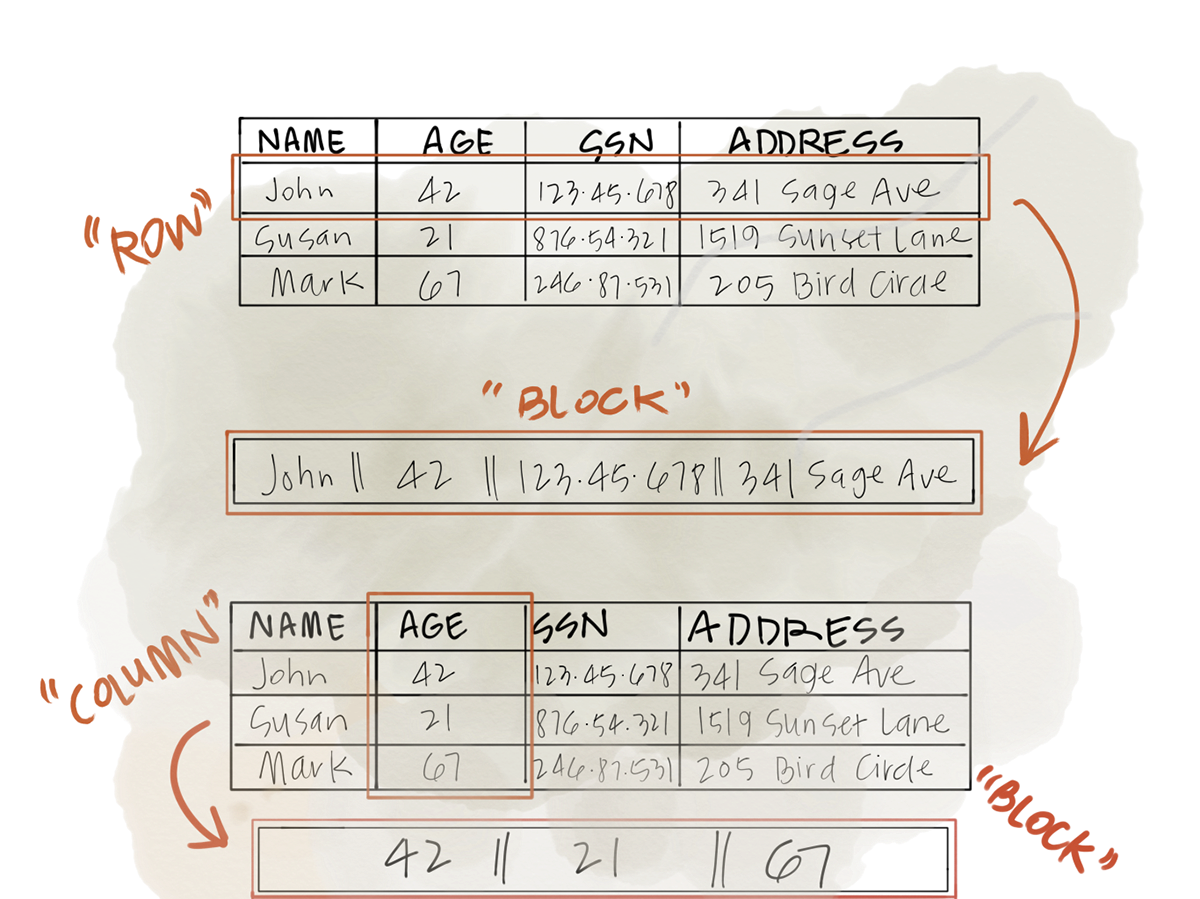
7. PySpark¶
Spark is a general-purpose computing framework that can scale to massive data volumes. It builds upon prior big data tools such as Hadoop and MapReduce while providing significant improvements in the expressivity of the languages it supports. One of the core components of Spark is resilient distributed datasets (RDD), which enable clusters of machines to perform workloads in a coordinated and fault-tolerant manner. In more recent versions of Spark, the Data frame API provides an abstraction on top of RDDs that resembles the same data structure in R and Pandas.
PySpark is the Python interface for Spark, and it provides an API for working with large-scale datasets in a distributed computing environment. PySpark provides a nice balance between expressive programming languages and APIs to Spark versus more legacy options such as MapReduce.
By using PySpark, we've been able to reduce the amount of support we need from engineering teams to scale up models from concept to production.
Scalability¶
While we are able to scale up models that serve multiple machines using Lambda, ECS, and GKS, these containers worked in isolation and there was no coordination among nodes in these environments. With PySpark, we can build model workflows that are designed to operate in cluster environments for both model training and model serving.
Usually, libraries like sklearn are used to develop models, and languages such as PySpark are used to scale up to the full player base.
Pandas dataframes¶
When we use toPandas or other commands to convert a dataset to a Pandas object, all of the data is loaded into memory on the driver node, which can crash the driver node when working with large datasets.
Pandas UDF¶
Pandas UDFs are user-defined functions that are executed by Spark using Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. Pandas UDFs can be used with PySpark to perform distributed-deep learning and feature engineering.
Lazy Execution¶
In PySpark, the majority of commands are lazily executed, meaning that an operation is not performed until the output is explicitly needed. While working with Spark Dataframes can seem to constrain us, the benefit is that PySpark can scale to much larger datasets than Pandas.
Spark deployment¶
- Self-hosted: An engineering team manages a set of clusters and provides console and notebook access.
- Cloud solutions: AWS provides a managed Spark option called EMR and GCP has
Cloud Dataproc.
- Vendor solutions: Databricks, Cloudera
Using a distributed computing environment means that we need to use a persistent file store such as GCS/S3 when saving data. This is important for logging because a worker node may crash and it may not be possible to ssh into the node for debugging. While PySpark can work with databases such as Redshift, it performs much better when using distributed file stores such as S3 or GCS.