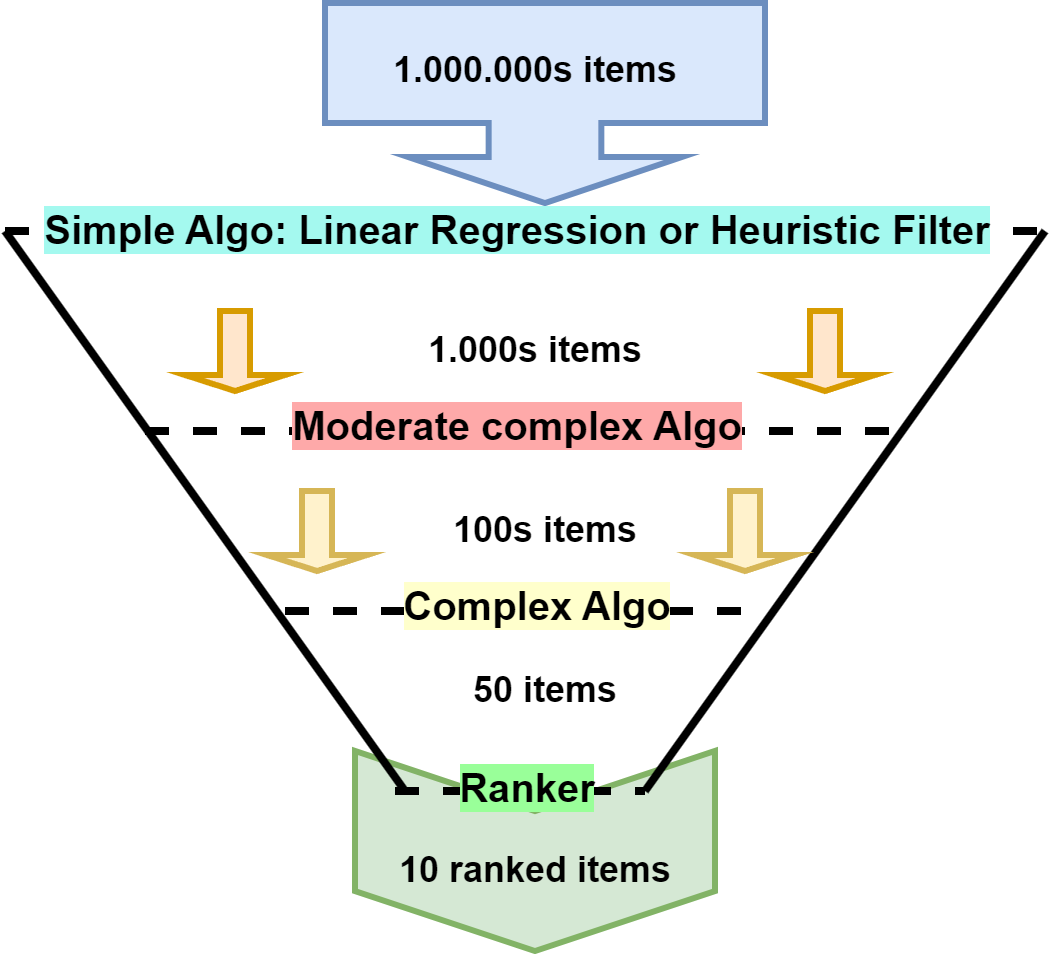
1.1 Amazon Elastic Compute (EC2)¶
When creating a virtual machine (which is an EC2 instance), create a key-pair (consisting of a private key and a public key, which is a set of security credentials that you use to prove your identity when connecting to an instance), add to the new EC2 instance and download the private key "*.pem" to access the server via ssh.
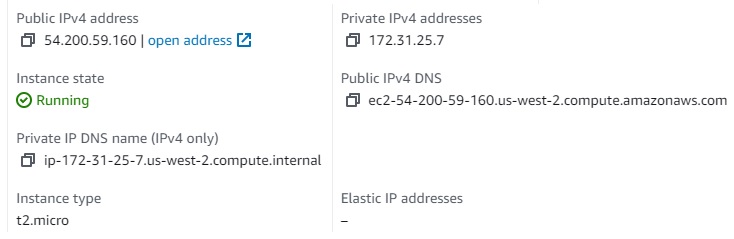
There are 2 IPs
Public IP (For SSH, or access Jupyter from external): 54.200.59.160
Private IP: 172.31.25.7 - internal IP for this virtual machine. When deploying services on this server, we config with this IP.
To log in, use ssh
$ ssh -i ".ssh\Scalable-Model-Pipelines-Key-Pair-Name.pem" ec2-user@ec2-54-200-59-160.us-west-2.compute.amazonaws.comRun Jupyter as background service if you want to work on Jupyter notebook:
$ nohup jupyter notebook --ip 172.31.25.7 --notebook-dir ~/codes/ &To access Jupyter, we need to create an "Inbound Rule" from the Amazon EC2 management website (choose current the security group > Actions > Edit Inbound Rules > Add a new rule to port 8888 by Jupyter)
After starting Jupyter, it will show a URL with a private token like this:
http://172.31.25.7:8888/?token=02d---------------------------b1
change this private IP to public IP to run in the local browser.
http://54.200.59.160:8888/?token=02d---------------------------b1
Note: Activate the env of conda before running jupyter