3. Batch Predicting Model¶
3.1 Google Cloud Dataflow¶
Dataflow is a tool for building data pipelines that can run locally or scale up to large clusters in a managed environment. We briefly talked about it in the last Chapter.
Now we will use Apache Beam to build a Predicting Service in the Google Cloud Dataflow environment
3.2 Process Data with DoFn¶
Below is a template of how we define a class of DoFn to predict each row (element) from data (for example, loaded from BigQuery). Because it separates the whole data, it can scale up to a massive processing data pipeline.
Prediction¶
import apache_beam as beam
class ApplyDoFn(beam.DoFn):
def __init__(self):
self._model = None
def process(self, element):
if self._model is None:
self._model = LOAD_MODEL
new_x = TRANSFORM(element)
prediction = self._model.predict(new_x)[0]
return [ { 'guid': element['guid'], 'prediction': prediction } ]
predictions = data | 'Apply Model' >> beam.ParDo(ApplyDoFn())
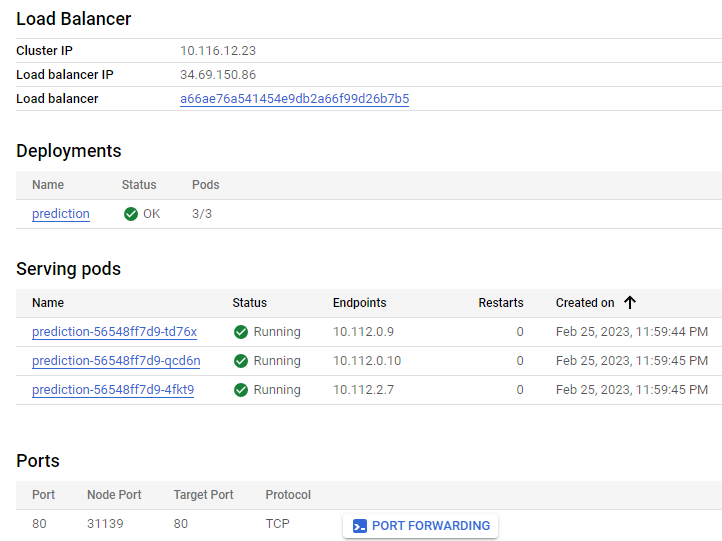
Now we can save the prediction results anywhere, it could be another table of BigQuery or a NoSQL DB such as Google Cloud Datastore
Save to Cloud Datastore¶
class PublishDoFn(beam.DoFn):
def __init__(self):
from google.cloud import datastore
self._ds = datastore
def process(self, element):
client = self._ds.Client()
entity = self._ds.Entity(client.key())
entity['prediction'] = element['prediction']
entity['time'] = element['time']
client.put(entity)
predictions | 'Create entities' >> beam.ParDo(PublishDoFn())